Today’s been a fun one. DigiCert decided to add its QuoVadis Global SSL ICA G3 intermediate certificate to its Certificate Revocation Lists last night - a certificate that was in the chain of hundreds of our servers.
Doing this without any announcement or notice wasn’t the greatest way to start work on a Friday morning, but hopefully this information will prove useful to some.
The new certificate (issued 2020-09-22) has the serial number of: 2d2c802018b7907c4d2d79df7fb1bd872727cc93
The old certificate (issued 2012-11-06) has the serial number of: 7ed6e79cc9ad81c4c8193ef95d4428770e341317
Thankfully, you can just go through and replace the intermediate certificate in your chain, without needing to issue new certificates, with the updated certificate available here: http://trust.quovadisglobal.com/qvsslg3.crt
We also developed a quick and dirty script to scan your network and look for web servers still serving up the old, revoked intermediate certificate. Just replace line 11 with your IP ranges as required:
We’ve just started making use of Sentry‘s On Premise offering in our environment, and were looking forward to integrating it into our Mattermost chat platform to alert developers of any issues.
Unfortunately, the only third party plugin I could find was a few years out of date and didn’t seem like it was compatible with newer versions of Sentry.
After a bit of playing around, I figured the easiest way was to just write an intermediary API to accept webhooks from Sentry, format a message, and pass it onto Mattermost. This is now working nicely in our environment.
Place the script on a web server, edit it to replace the placeholder variables I’ve left in.
In Sentry, go to Settings > Developer Settings > New Internal Integration. Give it a name, and set the ‘Webhook URL’ to the location of the above script. Grant the ‘Read’ permission for ‘Issue & Event’ and enable the ‘issue’ webhook trigger.
In Mattermost, create a new ‘Incoming Webhook‘ and add its URL to the script on line 39.
And you’re away! While it’d have been nice for us to have a native solution within Sentry, I didn’t want to spend the time writing my own Sentry plugins. This way seemed more flexible.
Back in November I was tasked with orchestrating the migration of over 200 virtual machines from our existing Hyper-V infrastructure onto our new, shiny VMware based infrastructure.
But with this came challenges; downtime needed to be minimized, and the whole process needed to go as smoothly as possible. With our Hyper-V servers rapidly running out of remaining warranty and support, it needed to be done quickly, too.
Windows VMs (mostly) went smoothly, so this post is going to focus on the guest OS that made up the majority of our fleet - Debian 9.
After migrating a few test VMs, it was clear that there were two main stages of the migration process:
Initially migrating the VM and getting it to boot
Configuring network interfaces and packages once running on VMware
As it’s already well documented, this blog post won’t go into detail regarding the process of shifting the VM disks from Hyper-V to VMware. For the record, we used VMware Converter, installed its server on a new VM, and installed the client application on our workstations. This worked incredibly well for us, and sped the process up a lot.
Once a VM was migrated, the operating system would refuse to boot. A few steps needed to be taken in order to get them to boot correctly, but this became muscle memory after a handful of VMs had been done.
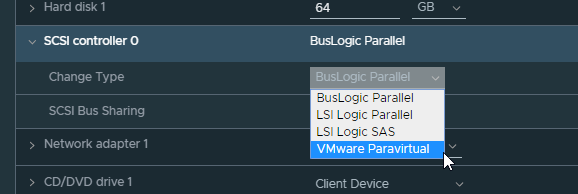
Firstly, the newly created VM would have its SCSI controller created as a “BusLogic Parallel” controller. This needed to be changed to “VMware Paravirtual” in order for the disk to be recognised at all.
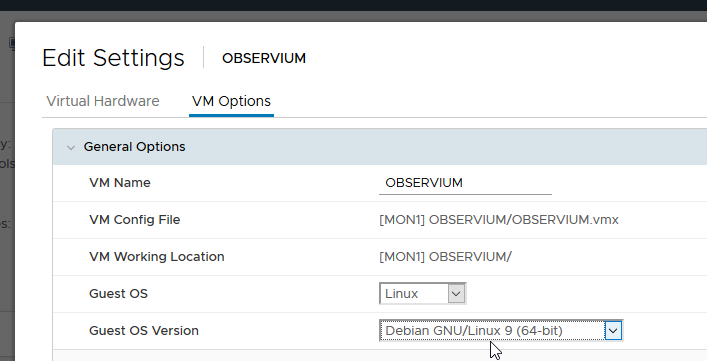
Then, the Guest OS setting also needed to be corrected, as well as forcing the VM into the EFI setup screen on next boot.
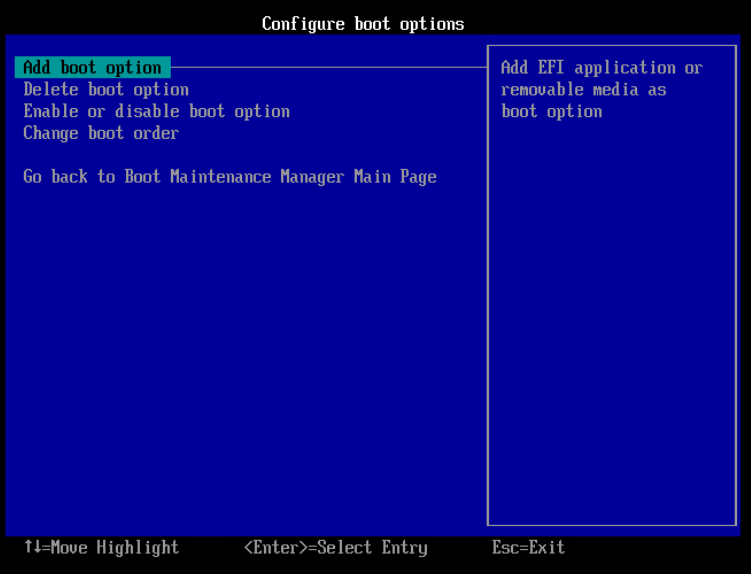
Power up the VM, and open the console. Use the arrow keys to navigate down and select the “Enter Setup“ menu, then “Configure boot options“, then “Add boot option“.
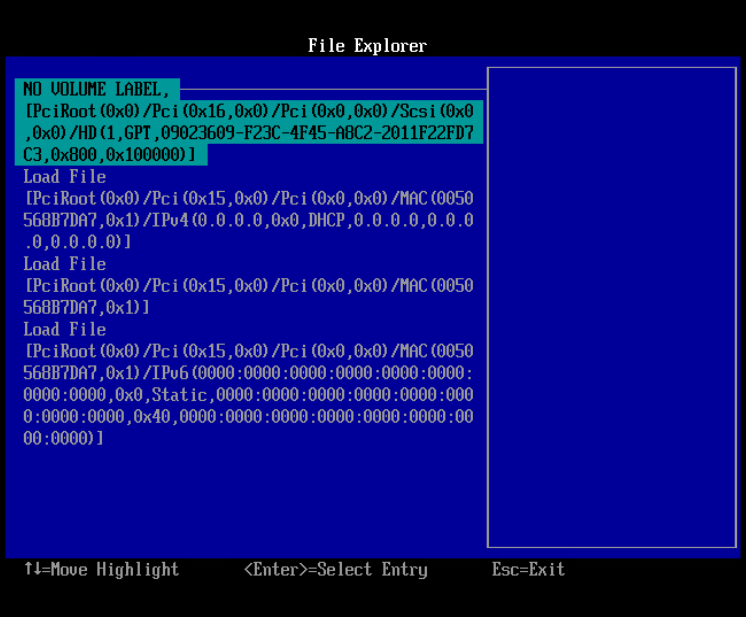
Then, you need to select the volume you’d like to add as a boot device. This is likely going to be the first option, always labelled “NO VOLUME LABEL” for every VM we migrated.
Once you’ve selected this disk, navigate through the file structure until you locate grubx64.efi, and select it. Scroll down to the “Input the description“ option and enter a sensible label. We used “Debian 9” for all of ours. Then select “Commit changes and exit”.
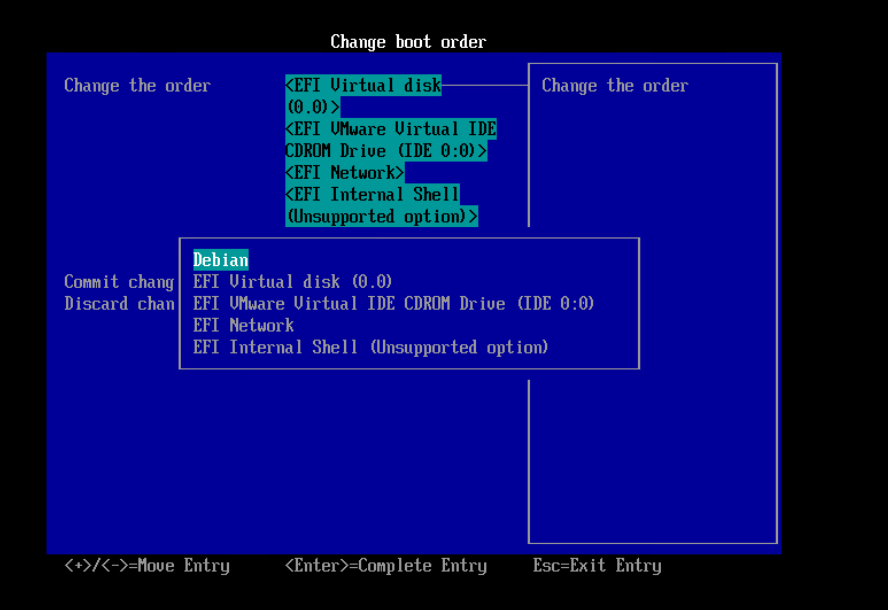
Navigate back a few menus, and select “Change boot order“ and then “Change the order“
Use the + key to move your new entry all the way to the top, and hit enter. Then select “Commit changes and exit“, “Exit the Boot Maintenance Manager“ then “Reset the System“.
The VM should now reset and successfully boot into your Debian operating system.
Once the VM was up and running on VMware, we were 99% of the way there. All that needed doing now was installing open-vm-tools and configuring the network interfaces. We found that once virtual machines had been migrated to VMware, interfaces previously eth0 renamed themselves to ens192. Some of these VMs were quite old, and didn’t use the systemd Predictable Network Interface Names, and we have a number of scripts hardcoded to use eth0 for networking.
To speed this process up and automate as much of it as possible, we used the following script:
if [ -f "/sys/class/net/ens192/address" ]; then # Temporarily bring up the network sed -i 's/eth0/ens192/g' /etc/network/interfaces service networking restart fi
# Set interfaces file back to eth0 sed -i 's/ens192/eth0/g' /etc/network/interfaces
# Update initramfs update-initramfs -u
fi
# Remove myself apt-get remove -y vmwaremigrate
echo"Done! VM Configured. Rebooting in 3 seconds..." sleep 3
# Reboot system reboot
This script was packaged as a Debian package called vmwaremigrate which was pre-installed on all our VMs prior to the installation. This meant that all that needed to be done was to log in to the VM through the console, run vmwaremigrate and you were done!
Overall, I’m very happy with how smoothly this process went. My colleagues and I managed to successfully migrate over 200 virtual machines in just shy of 3 weeks, limiting ourselves to around 10 a day to minimise disruption to users.
Tuesday mornings are our routine maintenance window, and today’s maintenance was upgrading our vSphere hosts to ESXi, 6.7.0, 16075168. We have a fairly standard, run of the mill deployment, so upgrades to hosts are pretty much the standard “select all hosts, hit ‘Remidate’, grab a coffee” type procedure.
As expected, our first host went into Maintenance Mode, patched itself, and powered down. However when it came back up, I was greeted with:
1
The object 'vim.Datastore:datastore-158' has already been deleted or has not been completely created.
Interestingly, I’d not come across this paticular issue before. It was related to vSphere HA (we have all our hosts in HA clusters), and that was stopping the host coming out of maintenance mode and the upgrade operation proceeding.
vCenter recommended I try the simple approach of clicking the rather aptly named “Reconfigure vSphere HA” button, so I tried this and attempted to take the host out of maintenance mode again. Same issue. Damn.
I looked back through our change history, and realised that one of the LUNs this host had access to was deleted not too long ago, which would explain our missing datastore error message.
vSphere HA, by default, will select two datastores as your ‘Heartbeat Datastores’. The issue here was that the deleted LUN had previously been selected by one of our hosts as a Heartbeat Datastore.
To resolve this issue, I performed the following steps:
Click on your Cluster within vCenter
Click on the ‘Configure’ tab
Click on the ‘vSphere Availability’ menu
Click ‘Edit’
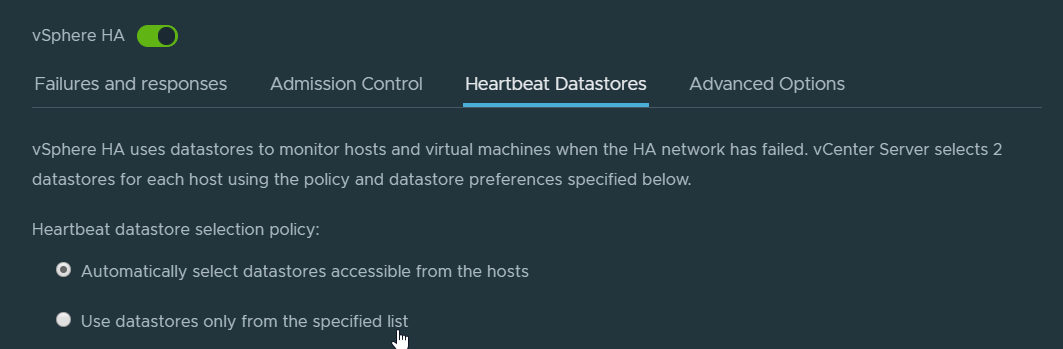
Click ‘Heartbeat Datastores’
Select Use datastores only from the specified list
Select any datastore which all your hosts have access to, and click OK
Proceed with your upgrade as before
Once your upgrade is complete, it’s probably advisable you change this option back to ‘Automatically select datastores accessible from the hosts’
Once this had been done, the issue went away, and our upgrade proceeded without issue.